



使用 Web Worker 提升大文件分片处理性能
0.准备demo
初始化项目
npm init -y安装依赖
npm install webpack webpack-cli spark-md5 --save-dev npm install webpack-dev-server html-webpack-plugin --save-dev项目结构
project/ ├── src/ │ ├── index.html │ ├── index.js │ ├── cutFile.js │ └── worker.js ├── webpack.config.js └── package.json配置文件
// webpack.config.js const path = require('path'); const HtmlWebpackPlugin = require('html-webpack-plugin'); module.exports = { mode: 'development', entry: './src/index.js', output: { path: path.resolve(__dirname, 'dist'), filename: 'main.js' }, plugins: [ new HtmlWebpackPlugin({ template: './src/index.html' }) ], devServer: { static: './dist', } };添加 npm scripts
{ "scripts": { "start": "webpack serve", "build": "webpack" }, "description": "", "devDependencies": { "html-webpack-plugin": "^5.6.3", "spark-md5": "^3.0.2", "webpack": "^5.97.1", "webpack-cli": "^6.0.1", "webpack-dev-server": "^5.2.0" } }源码
<!-- src/index.html --> <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>文件分片上传</title> </head> <body> <h1>大文件分片上传</h1> <input type="file" id="fileInput"> </body> </html>// src/index.js import { cutFile } from './cutFile'; document.getElementById('fileInput').onchange = async (e) => { console.time('分片计时'); const file = e.target.files[0]; const chunks = await cutFile(file); console.timeEnd('分片计时'); console.log('===所有分片===', chunks); };// src/cutFile.js import { createChunk } from './createChunk' // 假设和后端预定好了每个分片最大5M const CHUNK_SIZE = 5 * 1024 * 1024; export const cutFile = async (file) => { // 计算出分片的数量 const chunkCount = Math.ceil(file.size / CHUNK_SIZE) const result = [] for (let index = 0; index < chunkCount; index++) { const chunk = await createChunk(file, index, CHUNK_SIZE) result.push(chunk) } return result }// src/createChunk.js import SparkMD5 from 'spark-md5'; /** * 将文件分片的主函数 * @param {File} file - 用户选择的文件对象 * @returns {Promise<Array>} - 返回分片数组 */ export const createChunk = (file, index, chunkSize) => { return new Promise((resolve) => { const start = index * chunkSize const end = start + chunkSize // SparkMD5用于计算hash值 const spark = new SparkMD5.ArrayBuffer() const fileReader = new FileReader() // 每一片的blob对象 const blob = file.slice(start, end) fileReader.onload = (e) => { // 将分片内容添加到spark中 spark.append(e.target.result) // 返回这个分片的所有信息 resolve({ start, // 分片起始位置 end, // 分片结束位置 index, // 分片索引 hash: spark.end(), // 这一片的hash值 blob // 分片数据 }); } fileReader.readAsArrayBuffer(blob) }) }运行起来测试一下
npm run start
1.普通单线程分片
以上demo就是最基础的大文件分片,使用一个2.54G的视频文件测试一下完成分片需要多长时间
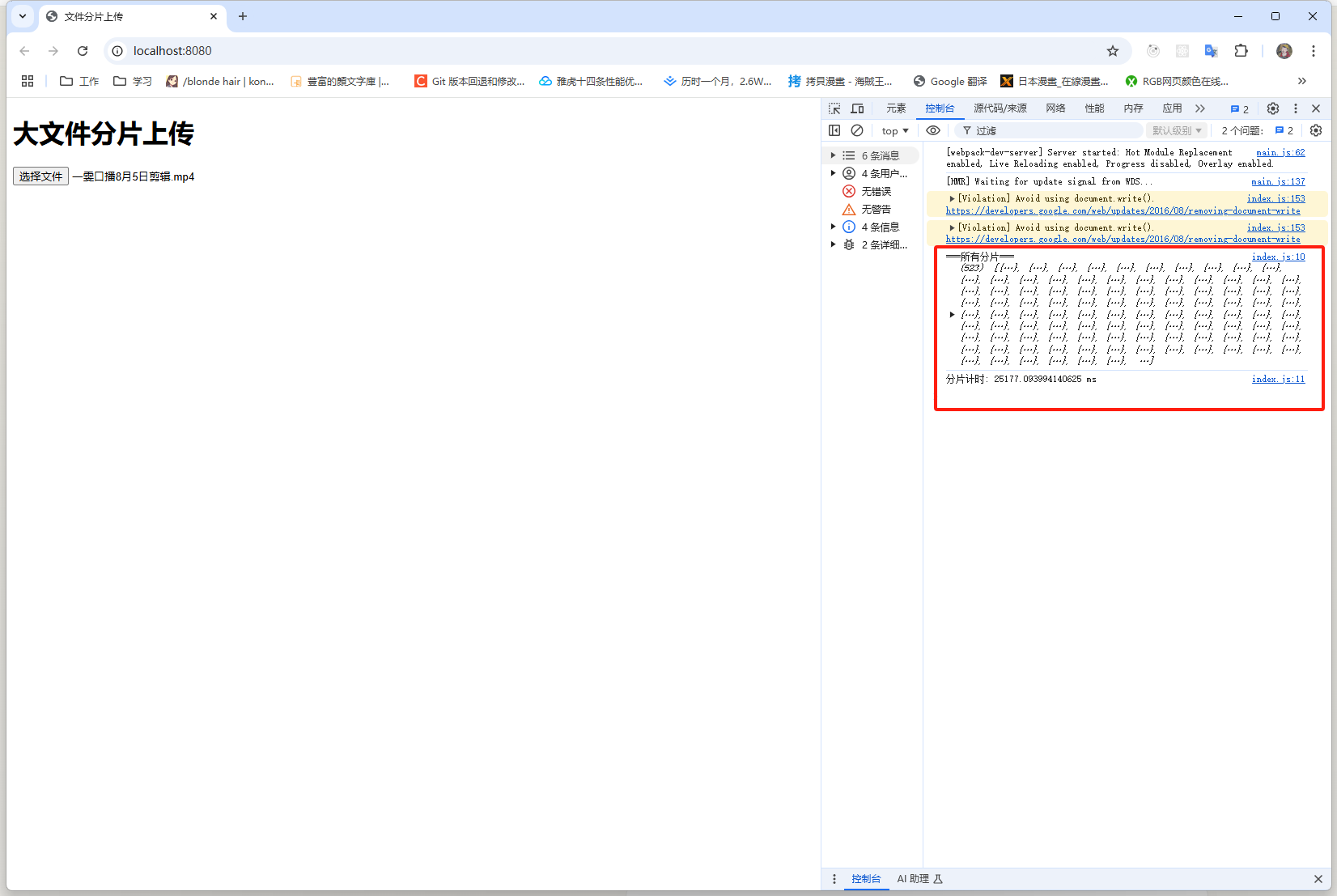
可以看到一共是523个分片,一共耗时是大约25s。
2.寻找原因
为什么分片会这么耗时,这时候可能会想到是不是cutFile方法写的有一些问题:
// cutFile.js
export const cutFile = async (file) => {
// 计算出分片的数量
const chunkCount = Math.ceil(file.size / CHUNK_SIZE)
const result = []
for (let index = 0; index < chunkCount; index++) {
// 可能会想到优化这个部分
const chunk = await createChunk(file, index, CHUNK_SIZE)
result.push(chunk)
}
return result
}改写后的方法
// cutFile.js
export const cutFile = async (file) => {
// 计算出分片的数量
const chunkCount = Math.ceil(file.size / CHUNK_SIZE)
// 创建一个数组来存储所有的分片Promise
const chunkPromises = [];
for (let index = 0; index < chunkCount; index++) {
chunkPromises.push(createChunk(file, index, CHUNK_SIZE))
}
// 等待所有分片创建完成
return await Promise.all(chunkPromises);
}然后再次尝试,发现时间没有缩短多少:
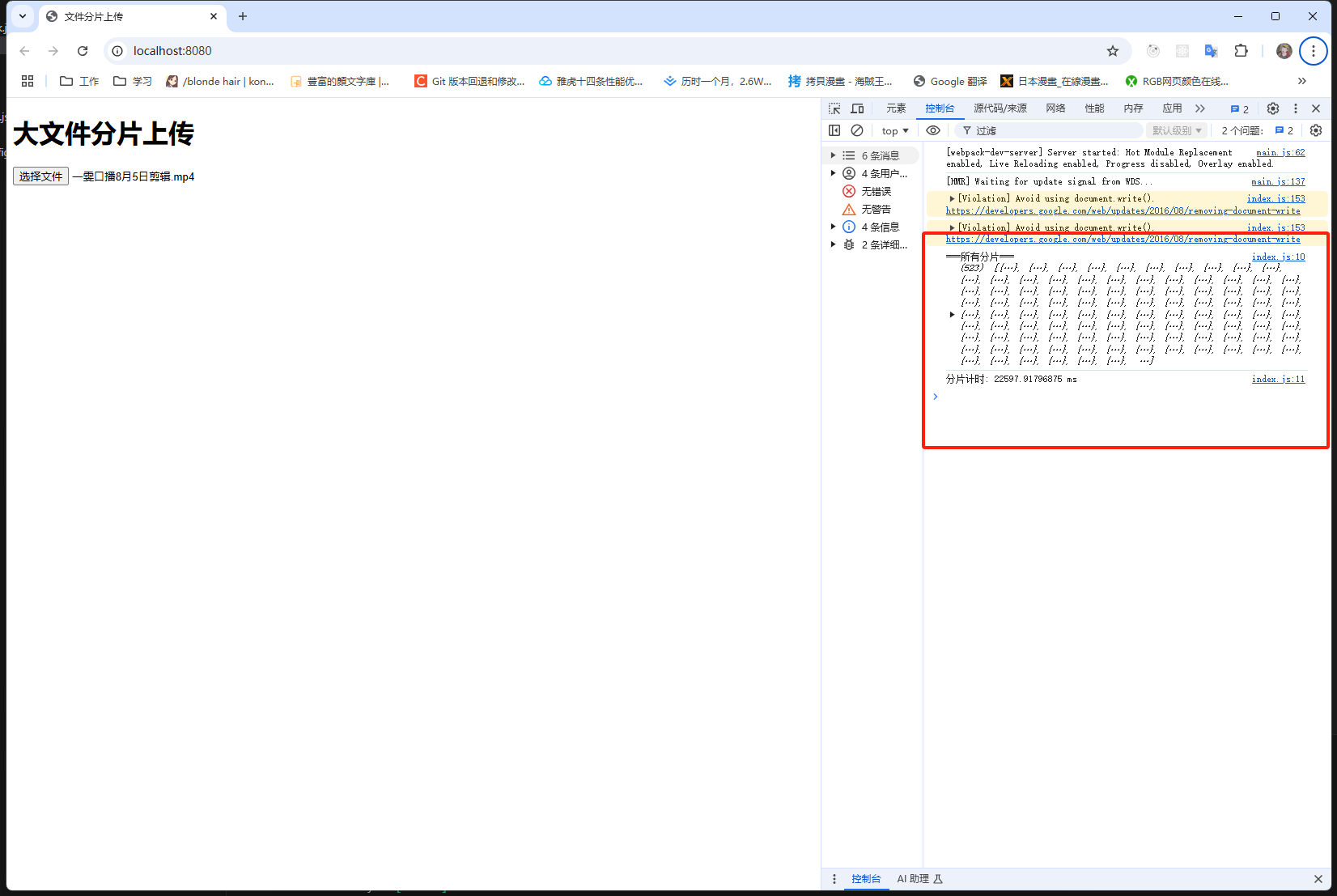
3.分片速度慢的真正原因
这里直接给出答案,感兴趣的可以自己慢慢调试,看看究竟是哪里耗时。
文件读取耗时
- 使用
FileReader读取每个分片到内存中 - 对于大文件来说,这个过程本身就很耗时
- 特别是
FileReader.readAsArrayBuffer()需要把文件内容完整加载到内存中
- 使用
计算hash耗时
- 每个分片都要即时计算 hash 值
- SparkMD5 的计算过程是 CPU 密集型的
- 所有操作都在主线程上执行,会阻塞界面
// createChunk.js
export const createChunk = (file, index, chunkSize) => {
return new Promise((resolve) => {
const start = index * chunkSize
const end = start + chunkSize
// SparkMD5用于计算hash值
const spark = new SparkMD5.ArrayBuffer()
const fileReader = new FileReader()
// 每一片的blob对象
const blob = file.slice(start, end)
fileReader.onload = (e) => {
// 将分片内容添加到spark中
spark.append(e.target.result)
// 返回这个分片的所有信息
resolve({
start, // 分片起始位置
end, // 分片结束位置
index, // 分片索引
hash: spark.end(), // 这一片的hash值
blob // 分片数据
});
}
fileReader.readAsArrayBuffer(blob)
})
}4.如何优化
了解完原因大概就能想到优化方案了,既然把这个hash的计算放到主线程上运行会很耗时,那么我们能不能把这个计算操作放到后台线程去做呢?
5.Web Worker
刚好Web Worker就提供了这个能力。
浏览器是单线程的
- JavaScript 默认运行在主线程上
- 主线程同时要处理 UI 渲染、用户交互等
- 当进行大量计算时,会导致主线程阻塞,界面卡顿
Web Worker 提供了多线程能力
- Worker 在后台线程运行
- 不会阻塞主线程
- 通过消息机制与主线程通信
6.多线程优化大文件分片
具体代码实现,改写cutFile.js和createChunk.js,另增加一个worker.js
// src/cutFile.js
// 计算出最大能开几个线程,标准就是有多少个cup有多少内核就开多少个
const MAX_THREADS = navigator.hardwareConcurrency || 4;
// 假设和后端预定好了分片大小为5M
const CHUNK_SIZE = 5 * 1024 * 1024
/**
* 将文件分片的主函数
* @param {File} file - 用户选择的文件对象
* @returns {Promise<Array>} - 返回分片数组
*/
export const cutFile = async (file) => {
return new Promise((resolve) => {
// 计算总分片数
const totalChunks = Math.ceil(file.size / CHUNK_SIZE);
// 实际使用的线程数量不应该超过分片数
const actualThreadCount = Math.min(MAX_THREADS, totalChunks);
// 存储每个线程的处理结果
const result = []
// 用来计数已完成的线程
let finishCount = 0
// 计算每个线程处理的分片数
const baseChunksPerWorker = Math.floor(totalChunks / actualThreadCount);
const extraChunks = totalChunks % actualThreadCount;
for (let i = 0; i < actualThreadCount; i++) {
// 开启一个线程任务
const start = i * baseChunksPerWorker + Math.min(i, extraChunks);
const end = start + baseChunksPerWorker + (i < extraChunks ? 1 : 0);
const worker = new Worker(new URL('./worker.js', import.meta.url));
// 发送消息
worker.postMessage({
file,
start,
end,
CHUNK_SIZE
})
worker.onmessage = e => {
// 关闭这个线程
worker.terminate();
result[i] = e.data
finishCount++
// 当finishCount的值等于线程数量,说明所有线程都结束了
if (finishCount === actualThreadCount) {
// 最后得到result的结果是 [[...],[...],[...]],所以要拍扁
resolve(result.flat())
}
}
}
})
}// src/createChunk.js
import SparkMD5 from 'spark-md5';
/**
* 创建单个分片并计算其hash值
* @param {File} file - 源文件
* @param {number} index - 分片索引
* @param {number} chunkSize - 分片大小
* @returns {Promise} - 返回包含分片信息的Promise
*/
export const createChunk = (file, index, chunkSize) => {
return new Promise((resolve) => {
const start = index * chunkSize
const end = start + chunkSize
// SparkMD5用于计算hash值
const spark = new SparkMD5.ArrayBuffer()
const fileReader = new FileReader()
// 每一片的blob对象
const blob = file.slice(start, end)
fileReader.onload = (e) => {
// 将分片内容添加到spark中
spark.append(e.target.result)
// 返回这个分片的所有信息
resolve({
start, // 分片起始位置
end, // 分片结束位置
index, // 分片索引
hash: spark.end(), // 这一片的hash值
blob // 分片数据
});
}
fileReader.readAsArrayBuffer(blob)
})
}// src/worker.js
import { createChunk } from "./createChunk"
onmessage = async (e) => {
const { file, start, end, CHUNK_SIZE } = e.data;
const chunkPromises = [];
for (let index = start; index < end; index++) {
chunkPromises.push(createChunk(file, index, CHUNK_SIZE));
}
const chunks = await Promise.all(chunkPromises);
postMessage(chunks);
};测试一下效果,发现时间缩短到了原来的1/10!

7.一些需要注意
各位在写demo测试的时候,尽量使用webpack或者使用Vue,React等等,因为:
- 所有依赖都通过
npm管理 Webpack会自动处理Worker和模块导入
一开始我自己在测试的时候,是直接写html和几个js文件的,但是发现Worker中导入模块有很多的坑,测试了很久都没有搞定,最终还是决定使用Webpack,果然一把过了。
然后在使用了Webpack后,这部分的代码:
// 在实际的项目中,这样写参数也是非常主流的,如果各位感兴趣可以搜素一下,尝试其他的写法
const worker = new Worker(new URL('./worker.js', import.meta.url));